Словари и множества в Python и асимптотика стандартных операций
Введение
Понятие сложности алгоритмов уже было рассмотрено в первом семестре, в основном в работах, связанных с сортировками. Цель данной работы понять трудоемкость стандартных процедур в языке python а так же разобраться с думя мощными концепциями - множество(set) и словарь(dict).
Трудоемкость будет рассмотренна на примере встроенных методов и операций классов list, dict, set.
Список (list)
Для начала вспомним операции работы со списками.
| Операция | Пример | Трудоемкость | Замечания |
| Взятие индекса | l[i] | O(1) | |
| Сохранение элемента | l[i] = 0 | O(1) | |
| Длина | len(l) | O(1) | |
| Добавление в конец | l.append(5) | O(1) | |
| Извлечение с конца | l.pop() | O(1) | |
| Очистка списка | l.clear() | O(1) | Аналогично l = [] |
| Срез(Slice) | l[a:b] | O(b-a) | |
| Расширение | l.extend(A) | O(len(A)) | Зависит только от длины A |
| Создание | list(A) | O(len(A)) | Зависит от длины A (итерируемый объект) |
| Проверка ==, != | l1 == l2 | O(N) | |
| Присваивание в срез | [a:b] = ... | O(N) | |
| Удаление элемента | del l[i] | O(N) | |
| Поиск элемента | x (not) in l | O(N) | Поиск работает за O(N) |
| Копирование списка | l.copy() | O(N) | То же самое что l[:], который O(N) |
| Удаление из списка | l.remove(..) | O(N) | |
| Извлечение элемента | l.pop(i) | O(N) | O(N-i): l.pop(0):O(N) (см. выше) |
| Экстремумы | min(l)/max(l) | O(N) | Поиск работает за O(N) |
| Обращение | l.reverse() | O(N) | |
| Итерирование | for v in l: | O(N) | |
| Сортировка | l.sort() | O(N Log N) | |
| Перемножение | k*l | O(k N) | 5*l будет за O(N), len(l)*l будет O(N**2) |
У разработчиков типа данных list Python было много вариантов каким сделать его во время реализации. Каждый выбор повлиял на то, как быстро список мог выполнять операции. Одно из решений было сделать список оптимальным для частых операций.
Индексирование и присваивание
Две частые операции - индексирование и присваивание на позицию индекса. В списках Python значения присваиваются и извлекаются из определенных известных мест памяти. Независимо от того, насколько велик список, индексный поиск и присвоение занимают постоянное количество времени и, таким образом их трудоемкость O(1).
Pop, Shift, Delete
Извлечение элемента(pop) из списка Python по умолчанию выполняется с конца, но, передавая индекс, вы можете получить элемент из определенной позиции. Когда pop вызывается с конца, операция имеет сложность O(1) , а вызов pop из любого места - O(n). Откуда такая разница?
Когда элемент берется из середины списка Python, все остальные элементы в списке сдвигаются на одну позицию ближе к началу. Это суровая плата за возможность брать индекс за O(1), что является более частой операцией.
По тем же причинам вставка в индекс - O(N); каждый последующий элемент должен быть сдвинут на одну позицию ближе к концу, чтобы разместить новый элемент. Неудивительно, что удаление ведет себя таким же образом.
Итерирование
Итерирование выполняется за O(N), потому что для итерации по N элементам требуется N шагов. Это также объясняет, почему оператор in, max, min в Python является O(N): чтобы определить, находится ли элемент в списке, мы должны перебирать каждый элемент.
Срезы
Чтобы получить доступ к фрагменту [a: b] списка, мы должны перебрать каждый элемент между индексами a и b. Таким образом, доступ к срезу - O(k), где k - размер среза. Удаление среза O(N) по той же причине, что удаление одного элемента - O(N): N последующих элементов должны быть смещены в сторону начала списка.
Умножение на int
Чтобы понять умножение списка на целое k, вспомним, что конкатенация выполняется за O(M), где M - длина добавленного списка. Из этого следует, что умножение списка равно O(N k), так как умножение k-размера списка N раз потребует времени k (N-1).
Разворот списка
Разворот списка - это O(N), так как мы должны переместить каждый элемент.
Упражнение №1
Допишите в следующем коде учаток функции, где repeat_count раз повторяется взятие операции pop по индексу pop_position. Сделается чтобы если pop_position == None то брался pop() без указания индекса. Допишите код получения массивов values1, values2, values3. Покажите преподавателю получившиеся графики.
import matplotlib.pyplot as plt
import time
def get_pop_time(size, repeat_count, pop_position=None):
'''
size - размер списка из нулей на котором будем тестировать скорость операции pop
repeat_count - количество повторений для усреднения
pop_position - позиция с которой делаем pop
'''
l = [0] * size
start_time = time.time()
#
# code here
#
end_time = time.time()
return (end_time - start_time) / repeat_count
repeat_count = 1000
# code here
values1 = [get_pop_time(...) for size in range(10, 1000)]
values2 = [get_pop_time(...) for size in range(10, 1000)]
values3 = [get_pop_time(...) for size in range(10, 1000)]
plt.plot(values1, label='Pop no args')
plt.plot(values2, label='Pop start list')
plt.plot(values3, label='Pop end list')
plt.ylabel('pop time')
ax = plt.subplot(111)
ax.legend()
plt.show()
Множество (set)
Множество в языке Python — это структура данных, эквивалентная множествам в математике. Элементы могут быть различных типов. Порядок элементов не определён.
Действия, которые можно выполнять с множеством:
- добавлять и удалять элементы,
- проверять принадлежность элемента множеству,
- перебирать его элементы,
- выполнять операции над множествами (объединение, пересечение, разность).
Операция “проверить принадлежность элемента” выполняется в множестве намного быстрее, чем в списке.
Элементами множества может быть любой неизменяемый тип данных: числа, строки, кортежи.
Изменяемые типы данных не могут быть элементами множества, в частности, нельзя сделать элементом множества список (вместо этого используйте неизменяемый кортеж) или другое множество. Требование неизменяемости элементов множества накладывается особенностями представления множества в памяти компьютера.
Задание множеств
Множество задается перечислением в фигурных скобках. Например:
A = {1, 2, 3}
Исключением явлеется пустое множество:
A = set() # A -- множество
D = {} # D -- не пустое множество, а пустой словарь!
Если функции set передать в качестве параметра список, строку или кортеж, то она вернет множество, составленное из элементов списка, строки, кортежа. Например:
>>> A = set('qwerty')
>>> print(A)
{'e', 'q', 'r', 't', 'w', 'y'}.
Каждый элемент может входить в множество только один раз.
>>> A = {1, 2, 3}
>>> B = {3, 2, 3, 1}
>>> print(A == B) # A и B — равные множества.
True
>>> set('Hello')
{'H', 'e', 'l', 'o'}
Работа с элементами множеств
| Операция | Значение | Трудоемкость |
|---|---|---|
x in A |
принадлежит ли элемент x множеству A (возвращают значение типа bool) |
O(1) |
x not in A |
то же, что not x in A |
O(1) |
A.add(x) |
добавить элемент x в множество A |
O(1) |
A.discard(x) |
удалить элемент x из множества A |
O(1) |
A.remove(x) |
удалить элемент x из множества A |
O(1) |
A.pop() |
удаляет из множества один случайный элемент и возвращает его | O(1) |
Как мы видим, по времени стандартные оперцаии с одним элементом множества выполняются за O(1).
Поведение discard и remove различается тогда, когда удаляемый элемент отсутствует в множестве:
discard не делает ничего, а метод remove генерирует исключение KeyError.
Метод pop также генерирует исключение KeyError, если множество пусто.
При помощи цикла for можно перебрать все элементы множества:
Primes = {2, 3, 5, 7, 11}
for num im Primes:
print(num)
Из множества можно сделать список при помощи функции list:
>>> A = {1, 2, 3, 4, 5}
>>> B = list(A)
[1, 2, 3, 4, 5]
Упражнение №2
Вывести на экран все элементы множества A, которых нет в множестве B.
A = set('bqlpzlkwehrlulsdhfliuywemrlkjhsdlfjhlzxcovt')
B = set('zmxcvnboaiyerjhbziuxdytvasenbriutsdvinjhgik')
for x in A:
...
Операции с множествами, обычные для математики
| Операция | Значение | Трудоемкость |
| A | B A.union(B) | Возвращает множество, являющееся объединением множеств A и B. | O(len(A)+len(B)) |
| A | = B A.update(B) | Записывает в A объединение множеств A и B. | O(len(A)+len(B)) |
| A & B A.intersection(B) | Возвращает множество, являющееся пересечением множеств A и B. | O(min(len(A), len(B)) |
| A &= B A.intersection_update(B) | Записывает в A пересечение множеств A и B. | O(min(len(A), len(B)) |
| A - B A.difference(B) | Возвращает разность множеств A и B (элементы, входящие в A, но не входящие в B). | O(len(A)+len(B)) |
| A -= B A.difference_update(B) | Записывает в A разность множеств A и B. | O(len(A)+len(B)) |
| A ^ B A.symmetric_difference(B) | Возвращает симметрическую разность множеств A и B (элементы, входящие в A или в B, но не в оба из них одновременно). | O(len(A)+len(B)) |
| A ^= B A.symmetric_difference_update(B) | Записывает в A симметрическую разность множеств A и B. | O(len(A)+len(B)) |
| A <= B A.issubset(B) | Возвращает True, если A является подмножеством B. | O(len(A)) |
| A >= B A.issuperset(B) | Возвращает True, если B является подмножеством A. | O(len(B)) |
| A < B | Эквивалентно A <= B and A != B | O(len(A)) |
| A > B | Эквивалентно A >= B and A != B | O(len(B)) |
В случае, если нужно провести процедуру, затрагивающую все элементы множества, то его трудоемкость будет O(N).
Упражнение №3
Даны четыре множества:
A = set('0123456789')
B = set('02468')
C = set('12345')
D = set('56789')
Найти элементы, принадлежащие множеству E:
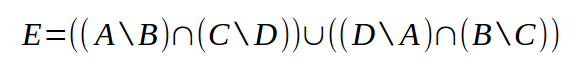
Словарь (ассоциативный массив, dict)
В массиве или в списке индекс - это целое число. Традиционной является следующая ситуация:
>>> Days = ['Sunday', 'Monday', 'Tuesday', 'Wednessday', 'Thursday', 'Friday', 'Saturday']
>>> Days[0]
'Sunday'
>>> Days[1]
'Monday'
А как реализовать обратное соответствие?
>>> Days['Sunday']
0
>>> Days['Monday']
1
При помощи списка или массива это сделать невозможно, нужно использовать ассоциативный массив или словарь.
В словаре индекс может быть любого неизменяемого типа! Индексы, как и сами хранимые значения, задаются явно:
Days = {
'Sunday': 0,
'Monday': 1,
'Tuesday': 2,
'Wednessday': 3,
'Thursday': 4,
'Friday': 5,
'Saturday': 6
}
>>> Days['Sunday']
0
>>> Days['Monday']
1
>>> Days['Yesterday']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Yesterday'
При попытке обратиться к несуществующему элементу ассоциативного массива мы получаем исключение KeyError.
Особенностью ассоциативного массива является его динамичность: в него можно добавлять новые элементы с произвольными ключами и удалять уже существующие элементы.
>>> Days['Yesterday'] = -1
>>> print(Days['Yesterday'])
-1
При этом размер используемой памяти пропорционален размеру ассоциативного массива. Доступ к элементам ассоциативного массива выполняется хоть и медленнее, чем к обычным массивам, но в целом довольно быстро.
Значения ключей уникальны, двух одинаковых ключей в словаре быть не может. А вот значения могут быть одинаковыми.
>>> Days['Tomorrow'] = -1
>>> Days['Yesterday'] == Days['Tomorrow']
True
Ключом может быть произвольный неизменяемый тип данных: целые и действительные числа, строки, кортежи. Ключом в словаре не может быть множество, но может быть элемент типа frozenset: специальный тип данных, являющийся аналогом типа set, который нельзя изменять после создания. Значением элемента словаря может быть любой тип данных, в том числе и изменяемый.
Создание словаря
Пустой словарь можно создать при помощи функции dict() или пустой пары фигурных скобок {} (вот почему фигурные скобки нельзя использовать для создания пустого множества).
Для создания словаря с некоторым набором начальных значений можно использовать следующие конструкции:
Capitals = {'Russia': 'Moscow', 'Ukraine': 'Kiev', 'USA': 'Washington'}
Capitals = dict(Russia = 'Moscow', Ukraine = 'Kiev', USA = 'Washington')
Capitals = dict([("Russia", "Moscow"), ("Ukraine", "Kiev"), ("USA", "Washington")])
Capitals = dict(zip(["Russia", "Ukraine", "USA"], ["Moscow", "Kiev", "Washington"]))
Также можно использовать генерацию словаря через Dict comprehensions:
Cities = ["Moscow", "Kiev", "Washington"]
States = ["Russia", "Ukraine", "USA"]
CapitalsOfState = {state: city for city, state in zip(Cities, States)}
Это особенно полезно, когда нужно "вывернуть" словарь наизнанку:
StateByCapital = {CapitalsOfState[state]: state for state in CapitalsOfState}
Операции с элементами словарей
| Операция | Значение | Трудоемкость |
| value = A[key] | Получение элемента по ключу. Если элемента с заданным ключом в словаре нет, то возникает исключение KeyError. | O(1) |
| value = A.get(key) | Получение элемента по ключу. Если элемента в словаре нет, то get возвращает None. | O(1) |
| value = A.get(key, default_value) | То же, но вместо None метод get возвращает default_value. | O(1) |
| key in A | Проверить принадлежность ключа словарю. | O(1) |
| key not in A | То же, что not key in A. | O(1) |
| A[key] = value | Добавление нового элемента в словарь. | O(1) |
| del A[key] | Удаление пары ключ-значение с ключом key. Возбуждает исключение KeyError, если такого ключа нет. | O(1) |
|
Удаление пары ключ-значение с предварительной проверкой наличия ключа. | O(1) |
|
Удаление пары ключ-значение с перехватыванием и обработкой исключения. | O(1) |
| value = A.pop(key) | Удаление пары ключ-значение с ключом key и возврат значения удаляемого элемента.Если такого ключа нет, то возбуждается KeyError. | O(1) |
| value = A.pop(key, default_value) | То же, но вместо генерации исключения возвращается default_value. | O(1) |
| A.pop(key, None) | Это позволяет проще всего организовать безопасное удаление элемента из словаря. | O(1) |
| len(A) | Возвращает количество пар ключ-значение, хранящихся в словаре. | O(1) |
Перебор элементов словаря по ключу
for key in A:
print(key, A[key])
Представления элементов словаря
Представления во многом похожи на списки, но они остаются связанными со своим исходным словарём и изменяются, если менять значения элементов словаря.
- Метод
keysвозвращает представление ключей всех элементов. - Метод
valuesвозвращает представление всех значений. - Метод
itemsвозвращает представление всех пар (кортежей) из ключей и значений.
>>> A = dict(a='a', b='b', c='c')
>>> k = A.keys()
>>> v = A.values()
>>> k, v
(dict_keys(['c', 'b', 'a']), dict_values(['c', 'b', 'a']))
>>> A['d'] = 'a'
>>> k, v
(dict_keys(['d', 'c', 'b', 'a']), dict_values(['a', 'c', 'b', 'a']))
Учтите что итерироваться по представлениям изменяя словарь нельзя
>>> for key in A.keys():
... del A[key]
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: dictionary changed size during iteration
Можно, если в начале скопировать представление в список
>>> for key in list(A.keys()):
... del A[key]
...
>>> A
{}
Пример использования словаря
# Создадим пустой словать Capitals
Capitals = dict()
# Заполним его несколькими значениями
Capitals['Russia'] = 'Moscow'
Capitals['Ukraine'] = 'Kiev'
Capitals['USA'] = 'Washington'
# Считаем название страны
print('В какой стране вы живете?')
country = input()
# Проверим, есть ли такая страна в словаре Capitals
if country in Capitals:
# Если есть - выведем ее столицу
print('Столица вашей страны', Capitals[country])
else:
# Запросим название столицы и добавим его в словарь
print('Как называется столица вашей страны?')
city = input()
Capitals[country] = city
Трудоемкость стандартных операций
Второй основной тип данных Python - это словарь. Как вы помните, словарь отличается от списка возможностью доступа к элементам по ключу, а не позиции. На данный момент наиболее важной характеристикой является то, что получение и присваивание элемента в словаре являются операциями за O(1).
Мы не будем пытаться пока дать интуитивное объяснение этому, но будьте уверены, что позже мы обсудим реализации словарей. Пока просто помните, что словари были созданы специально для того, чтобы как можно быстрее получить и установить значения по ключу.
Другая важная операция словаря - проверка наличия ключа в словаре. Операция contains также работает за O(1) (в случае со списками это занимало O(N)), потому что проверка для данного ключа подразумевает простое получение элемента по ключу, которое делается за O(1).
Когда нужно использовать словари
Словари нужно использовать в следующих случаях:
- Подсчет числа каких-то объектов. В этом случае нужно завести словарь, в котором ключами являются объекты, а значениями — их количество.
- Хранение каких-либо данных, связанных с объектом. Ключи — объекты, значения — связанные с ними данные. Например, если нужно по названию месяца определить его порядковый номер, то это можно сделать при помощи словаря
Num['January'] = 1; Num['February'] = 2; ... - Установка соответствия между объектами (например, “родитель—потомок”). Ключ — объект, значение — соответствующий ему объект.
- Если нужен обычный массив, но при этом масимальное значение индекса элемента очень велико, но при этом будут использоваться не все возможные индексы (так называемый “разреженный массив”), то можно использовать ассоциативный массив для экономии памяти.
Практическая работа по использованию словарей
Упражнение №4. Подсчет слов
Дан текст на некотором языке. Требуется подсчитать сколько раз каждое слово входит в этот текст и вывести десять самых часто употребяемых слов в этом тексте и количество их употреблений.
В качестве примера возьмите файл с текстом лицензионного соглашения Python /usr/share/licenses/python/LICENSE.
Подсказка №1: Используйте словарь, в котором ключ -- слово, а знчение -- количество таких слов.
Подсказка №2: Точки, запятые, вопросы и восклицательные знаки перед обработкой замените пробелами(используйте punctuation из модуля string).
Подсказка №3: Все слова приводите к нижнему регистру при помощи метода строки lower().
Подсказка №4: По окончании сбора статистики нужно пробежать по всем ключам из словаря и найти ключ с максимальным значением.
Упражнение №5. Перевод текста
Дан словарь task4/en-ru.txt с однозначным соответствием английских и русских слов в таком формате:
cat - кошка
dog - собака
mouse - мышь
house - дом
eats - ест
in - в
too - тоже
Здесь английское и русское слово разделены двумя табуляциями и минусом: '\t-\t'.
В файле task4/input.txt дан текст для перевода, например:
Требуется сделать подстрочный перевод с помощью имеющегося словаря и вывести результат в output.txt.
Незнакомые словарю слова нужно оставлять в исходном виде.
Упражнение №6. Страны и Языки
Дан список стран и языков на которых говорят в этой стране в формате <Название Страны> : <язык1> <язык2> <язык3> ... в файле task5/input.txt. На ввод задается N - длина списка и список языков. Для каждого языка укажите, в каких странах на нем говорят.
| Ввод | Вывод |
|---|---|
| 3 | |
| азербайджанский | Азербайджан |
| греческий | Кипр Греция |
| китайский | Китай Сингапур |
Упражнение №7*. Сделать русско-английский словарь
В файле task6/en-ru.txt находятся строки англо-русского словаря в таком формате:
Здесь английское слово (выражение) и список русских слов (выражений) разделены двумя табуляциями и минусом: '\t-\t'.
Требуется создать русско-английский словарь и вывести его в файл ru-en.txt в таком формате:
Порядок строк в выходном файле должен быть словарным с человеческой точки зрения (так называемый лексикографический порядок слов). То есть выходные строки нужно отсортировать.
Упражнение №8*. Синхронизация словарей
Даны два файла словарей: task7/en-ru.txt и task7/ru-en.txt (в формате, описанном в упражнении №6).
en-ru.txt:
ru-en.txt:
Требуется синхронизировать и актуализировать их содержимое.
en-ru.txt:
ru-en.txt:
Упражнение №9*. Добродушные соседи
В одном очень дружном доме, где живет Фёдор, многие жильцы оставляют ключи от квартиры соседям по дому, например на случай пожара или потопа, да и просто чтобы покормили животных или полили цветы.
Вернувшись домой после долгих странствий, Фёдор обнаруживает, что потерял свои ключи и соседей дома нет. Но вдруг у домофона он находит чужие ключи. Помогите Федору найти ключи от своей квартиры в квартирах соседей.
На ввод подается файл input.txt, в котором в первой строке записано три числа через пробел N - номер квартиры Фёдора, M - номер квартиры от которой Федор нашел ключи, K - ключ от этой квартиры. Далее i-я строка хранит описание ключей запертых в i-й квартире в формате <m_i0 - номер квартиры> <k_i0 - ключ>,<m_i1 - номер квартиры> <k_i1 - ключ>,... , причем реальные номера квартир "зашифрованы" ключем от i-й квартиры(Ki) и находятся по формуле m_ij' = m_ij - Ki. Номера квартир начинаются с 0 (кпримеру вторая строка файла соответствует 0-й квартире).
Нужно вывести ключ от квартиры Федора или None если его найти не получилось.
| Ввод | Вывод |
|---|---|
| 4 0 1 | 1 |
| 1 1,2 0,3 1,4 0 | |
| 3 0 | |
| 5 1,6 0 | |
| 1 1 | |
| 2 1 |
Подсказка: используйте словарь для хранения ключей от еще не открытых комнат и множество для уже проверенных комнат.
Упражнение №10*. Факультативно: генератор бреда
Дан текст-образец, по которому требуется сделать генератор случайного бреда на основе Марковских цепей.
Подробности спрашивайте у семинариста.